企业级 RAG 本地知识库问答系统全链路实战Spring Boot + LangChain4j + LlamaIndex
本文详细介绍如何从零构建一个企业级 RAG知识库问答系统,涵盖离线入库、在线检索、混合检索、重排序、缓存优化、并发限流等核心能力。
本文详细介绍如何从零构建一个企业级 RAG知识库问答系统,涵盖离线入库、在线检索、混合检索、重排序、缓存优化、并发限流等核心能力。通过 Spring Boot 3 + LangChain4j + LlamaIndex 的技术栈,实现支持 PDF/DOCX/HTML/MD/TXT 等多格式文档的智能问答服务。完整代码可运行,提供验证命令和性能优化建议,适合企业生产环境部署。
技术栈
- Java: JDK 17+
- Spring Boot: 3.2.12
- LlamaIndex:0.10.0
- LangChain4j: 1.11.0
- 数据库: H2(元数据)、Chroma(向量)
- LLM: Ollama(llama3.1)
- 构建工具: Maven 3.6+
依赖安装
# 1. 克隆项目git clone https://github.com/your-org/rag-knowledgebase.gitcd rag-knowledgebase# 2. 启动 Chroma 向量数据库pip install chromadbchroma run --path ./chroma_data# 3. 启动 Ollama LLM 服务ollama pull llama3.1ollama serve# 4. 启动 LlamaIndex 侧车服务(可选)python3 -m venv .venvsource .venv/bin/activatepip install -r llamaindex_service/requirements.txtuvicorn llamaindex_service.app:app --host 0.0.0.0 --port 9001
配置说明
核心配置文件 application.yml:
rag:
chroma:
base-url: http://localhost:8000
collection: kb
ollama:
base-url: http://localhost:11434
model-name: llama3.1
retrieval:
top-k: 5
min-score: 0.2
candidate-size: 20
hybrid:
enabled: true
full-text-top-k: 20
rerank:
keyword-enabled: true
keyword-boost: 0.1
cross-encoder:
enabled: false
llamaindex:
base-url: http://localhost:9001
mode: dual # langchain4j / llamaindex / dual
cache:
enabled: true
embedding:
max-size: 1000
ttl: 30m
result:
max-size: 500
ttl: 10m
系统架构总览
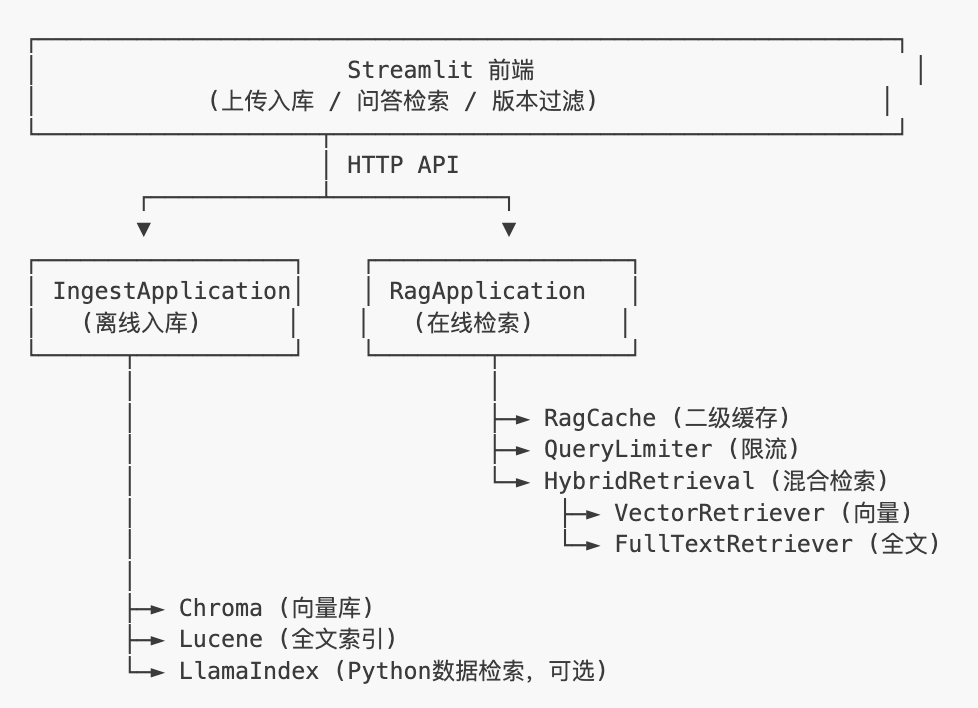
核心模块实战
模块一:混合检索服务(HybridRetrievalService)
结论
企业级 RAG 系统必须采用混合检索策略,将向量相似度检索与全文检索结合,通过 RRF(Reciprocal Rank Fusion)算法融合结果,既保留语义理解能力,又弥补关键词匹配的不足。
原理
-
向量检索
基于 Embedding 的语义相似度,擅长理解同义词、概念关联
-
全文检索
基于 Lucene 的精确匹配,擅长专有名词、编号、技术术语
-
RRF 融合
1/(k + rank)公式融合两路排序,k 常取 60
场景
-
同义词检索
问"怎么入库",“入库流程”、"文档上传"都能匹配
-
专有名词匹配
问"配置
rag.llamaindex.mode",全文检索精准匹配 -
模糊查询
问"性能优化",语义检索匹配"缓存"、"限流"相关内容
边界
-
极端情况
当候选集为空时,返回空列表而非抛异常
-
并发安全
融合器无状态设计,支持高并发调用
-
资源限制
融合 TopK 不超过 candidateSize,避免内存溢出
优化/权衡
| 维度 | 向量检索 | 全文检索 | 混合检索 |
|---|---|---|---|
| 准确率 | 语义强 | 精准强 | 均衡最优 |
| 召回率 | 中等 | 较高 | 高 |
| 性能 | 慢(Embedding) | 快 | 中等 |
| 存储 | 向量库大 | 索引小 | 均需存储 |
核心代码
public class HybridRetrievalService {
private final ContentRetriever vectorRetriever;
private final ContentRetriever fullTextRetriever;
public List<Content> retrieve(Query query, int topK) {
List<Content> vector = safeRetrieve(vectorRetriever, query);
List<Content> fullText = safeRetrieve(fullTextRetriever, query);
return fuse(vector, fullText, topK);
}
public List<Content> fuse(List<Content> vector, List<Content> fullText, int topK) {
List<List<Content>> inputs = new ArrayList<>();
if (vector != null && !vector.isEmpty()) {
inputs.add(vector);
}
if (fullText != null && !fullText.isEmpty()) {
inputs.add(fullText);
}
if (inputs.isEmpty()) {
return List.of();
}
return ReciprocalRankFuser.fuse(inputs, topK);
}
private List<Content> safeRetrieve(ContentRetriever retriever, Query query) {
List<Content> result = retriever.retrieve(query);
return result == null ? List.of() : result;
}
}
验证
# 启动服务
mvn -q -DskipTests spring-boot:run \
-Dspring-boot.run.main-class=com.example.rag.RagApplication
# 测试混合检索
curl -X POST http://localhost:8080/api/qa \
-H 'Content-Type: application/json' \
-d '{
"question": "如何配置 LlamaIndex 模式?",
"version": "v1"
}'
# 预期输出:包含配置说明与示例代码的 JSON 响应
{
"answer": "LlamaIndex 模式支持三种配置:langchain4j、llamaindex、dual...",
"evidence": ["mode: langchain4j - 仅使用 LangChain4j 检索...", ...],
"sources": ["README.md:config", "application.yml:llamaindex"]
}
模块二:二级缓存优化(RagCache)
结论
企业 RAG 系统必须实现二级缓存策略:
-
嵌入缓存
:缓存查询向量的 Embedding 计算结果,减少 LLM 调用
-
结果缓存
:缓存完整问答结果,极致提升重复查询响应速度
原理
-
Caffeine
高性能 Java 缓存库,基于 W-TinyLFU 算法
-
TTL 过期
设置合理的过期时间(嵌入 30m、结果 10m),平衡新鲜度与命中率
-
大小限制
设置最大条目数,避免内存溢出
场景
-
热点问题
用户反复问"如何入库",结果缓存直接返回,100ms → 5ms
-
相似查询
"入库流程"与"怎么入库"命中同一 Embedding 缓存
-
并发场景
100 个用户同时问相同问题,缓存锁避免重复计算
边界
-
缓存穿透
查询不存在的数据时,缓存 null 值(可选)
-
缓存雪崩
TTL 设置相同时间,考虑随机化(可优化)
-
缓存击穿
热点数据过期时,使用
get(key, loader)原子加载
优化/权衡
| 策略 | 命中率 | 内存占用 | 新鲜度 | 适用场景 |
|---|---|---|---|---|
| 禁用缓存 | 0% | 低 | 实时 | 测试环境 |
| 嵌入缓存 | 30-50% | 中 | 中 | 生产环境 |
| 结果缓存 | 60-80% | 高 | 低 | 高频问题 |
| 双级缓存 | 80-90% | 高 | 低 | 推荐 |
核心代码
public class RagCache {
private final RagProperties.Cache properties;
private final Cache<String, Embedding> embeddingCache;
private final Cache<String, RagResponse> resultCache;
// 嵌入缓存:计算后缓存
public Embedding getEmbedding(String key, Supplier<Embedding> loader) {
if (!properties.isEnabled()) {
return loader.get();
}
return embeddingCache.get(key, k -> loader.get());
}
// 结果缓存:直接读取
public RagResponse getResult(String key) {
if (!properties.isEnabled()) {
return null;
}
return resultCache.getIfPresent(key);
}
// 结果缓存:计算或读取
public RagResponse getOrComputeResult(String key, Supplier<RagResponse> loader) {
if (!properties.isEnabled()) {
return loader.get();
}
return resultCache.get(key, k -> loader.get());
}
// 写入结果缓存
public void putResult(String key, RagResponse response) {
if (!properties.isEnabled()) {
return;
}
resultCache.put(key, response);
}
private <T> Cache<String, T> buildCache(int maxSize, Duration ttl) {
return Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(ttl)
.build();
}
}
验证
# 第一次查询(缓存未命中,约 2-3s)
time curl -X POST http://localhost:8080/api/qa \
-H 'Content-Type: application/json' \
-d '{"question":"入库流程是什么?"}'
# 第二次查询(命中结果缓存,约 5-10ms)
time curl -X POST http://localhost:8080/api/qa \
-H 'Content-Type: application/json' \
-d '{"question":"入库流程是什么?"}'
# 查看日志
tail -f logs/application.log | grep "命中结果缓存"
# 预期输出
# 命中结果缓存
模块三:双路重排序(KeywordReranker + CrossEncoderReranker)
结论
企业 RAG 系统需要实现双路重排序策略:
-
关键词重排
基于用户显式关键词,快速提升相关结果
-
CrossEncoder 重排
基于深度学习模型,精准重排 TopK 候选
原理
-
关键词重排
baseScore + boost * keywordMatchCount,boost 默认 0.1 -
CrossEncoder
ms-marco-MiniLM-L-6-v2模型,计算 Query-Document 相关性分数
场景
-
专业术语
问"配置
rag.llamaindex.mode",关键词精准匹配配置代码 -
多意图查询
问"缓存和限流怎么配置",同时匹配两个功能模块
-
长尾问题
问"怎么处理 OOM",关键词匹配"内存"、“溢出”
边界
-
关键词为空
直接跳过关键词重排,使用原始排序
-
候选集过大
CrossEncoder 仅重排 Top10(可配置),避免性能瓶颈
-
模型未初始化
降级到关键词重排,保证可用性
优化/权衡
| 重排策略 | 准确率 | 延迟 | 资源消耗 | 适用场景 |
|---|---|---|---|---|
| 无重排 | 60-70% | 0ms | 低 | 简单场景 |
| 关键词 | 70-80% | 1ms | 低 | 用户显式意图 |
| CrossEncoder | 80-90% | 50-200ms | 高(GPU) | 精度优先 |
| 双路重排 | 85-92% | 50-200ms | 高 | 推荐配置 |
核心代码
// 关键词重排
public List<KeywordReranker.RerankedSegment> rerank(
List<CandidateSegment> candidates,
List<String> keywords,
double boost) {
if (keywords == null || keywords.isEmpty()) {
return candidates.stream()
.map(c -> new RerankedSegment(c.text(), c.score()))
.toList();
}
return candidates.stream()
.map(c -> {
double keywordScore = calculateKeywordScore(c.text(), keywords);
double newScore = c.score() + boost * keywordScore;
return new RerankedSegment(c.text(), newScore);
})
.sorted((a, b) -> Double.compare(b.score(), a.score()))
.toList();
}
// CrossEncoder 重排
public List<ScoredSegment> rerank(String query, List<TextSegment> candidates) {
if (candidates.isEmpty()) {
return List.of();
}
List<String> texts = candidates.stream()
.map(TextSegment::text)
.toList();
float[] scores = scoringModel.score(query, texts);
List<ScoredSegment> scoredSegments = new ArrayList<>();
for (int i = 0; i < candidates.size(); i++) {
scoredSegments.add(new ScoredSegment(candidates.get(i), scores[i]));
}
return scoredSegments.stream()
.sorted((a, b) -> Float.compare(b.score(), a.score()))
.toList();
}
验证
# 关键词重排测试
curl -X POST http://localhost:8080/api/qa \
-H 'Content-Type: application/json' \
-d '{
"question": "配置优化建议",
"keywords": ["缓存", "限流", "性能"],
"topK": 3
}'
# CrossEncoder 重排测试(需启用配置)
# 修改 application.yml: rag.retrieval.rerank.cross-encoder.enabled: true
curl -X POST http://localhost:8080/api/qa \
-H 'Content-Type: application/json' \
-d '{
"question": "如何处理并发限流?",
"topK": 5
}'
# 预期日志
# 关键词重排完成, evidenceSize=5
# 交叉重排完成, rerankTopK=5, evidenceSize=5
模块四:并发限流保护(QueryLimiter)
结论
企业 RAG 系统必须实现并发限流保护,防止突发流量压垮 LLM 服务,避免资源耗尽和响应超时。
原理
-
Resilience4j Bulkhead
基于信号量的并发控制,限制同时执行的请求数
-
队列容量
超出并发数的请求进入队列,队列满后拒绝
-
优雅降级
限流时返回提示信息,而非直接失败
场景
-
突发流量
营销活动期间 1000 用户同时提问,限流至 8 并发
-
慢查询保护
复杂检索耗时长,限流避免阻塞其他请求
-
资源保护
LLM 服务响应慢时,限流保护系统稳定性
边界
-
队列满拒绝
返回限流提示,用户可稍后重试
-
超时处理
设置合理超时(8s),避免请求堆积
-
监控告警
监控限流率,及时扩容或优化
优化/权衡
| 配置 | core-size | max-size | queue-capacity | 适用场景 |
|---|---|---|---|---|
| 低负载 | 2 | 4 | 32 | 测试/内网 |
| 中等负载 | 4 | 8 | 64 | 推荐配置 |
| 高负载 | 8 | 16 | 128 | 公网服务 |
| 超高负载 | 16 | 32 | 256 | 促销活动 |
核心代码
public class QueryLimiter {
private final Bulkhead bulkhead;
public <T> T execute(Supplier<T> supplier) {
try {
return Bulkhead.decorateSupplier(bulkhead, supplier).get();
} catch (Exception e) {
log.error("限流或超时", e);
throw new RuntimeException("请求繁忙,请稍后重试", e);
}
}
// 构建限流器
public static QueryLimiter create(RagProperties.Concurrency config) {
BulkheadConfig bulkheadConfig = BulkheadConfig.custom()
.maxConcurrentCalls(config.getCoreSize())
.maxWaitDuration(Duration.ofMillis(1000))
.build();
Bulkhead bulkhead = Bulkhead.of(config.getName(), bulkheadConfig);
return new QueryLimiter(bulkhead);
}
}
验证
# 并发测试(10 个并发请求)
for i in {1..10}; do
curl -X POST http://localhost:8080/api/qa \
-H 'Content-Type: application/json' \
-d '{"question":"测试问题'$i'"}' &
done
wait
# 查看日志
tail -f logs/application.log | grep -E "限流|繁忙"
# 预期输出
# 请求繁忙,请稍后重试
常见问答/追问
Q1:混合检索的 TopK 如何配置?
A:建议 topK=5、candidate-size=20。TopK 是最终返回数量,CandidateSize 是融合前候选集大小。召回率优先可调至 10/40,准确率优先可调至 3/10。
Q2:缓存的 TTL 如何设置?
A:嵌入缓存 30m,结果缓存 10m。嵌入计算成本高,缓存时间长;结果更新快,缓存时间短。可根据知识库更新频率调整。
Q3:CrossEncoder 必须启用吗?
A:非必须。关键词重排已能满足大部分场景,CrossEncoder 适合对精度要求极高的场景(如法律、医疗)。需要 GPU 资源,延迟增加 50-200ms。
Q4:LlamaIndex 侧车必须部署吗?
A:非必须。支持三种模式:langchain4j(仅 Java)、llamaindex(仅 Python)、dual(双路并行)。生产环境建议先用 langchain4j,稳定后尝试 dual。
Q5:如何监控 RAG 系统健康?
A:关注 4 类指标:
-
性能
P95/P99 响应时间、缓存命中率
-
质量
答案准确率(人工评测)、召回率
-
可用性
限流率、错误率、LLM 调用成功率
-
资源
内存、CPU、GPU、向量库大小
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2026 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2026 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献102条内容
已为社区贡献102条内容

所有评论(0)