Spark安装配置2_class
·
Kafka
1 . 进入kafka 目录, 启动 Zookeeper
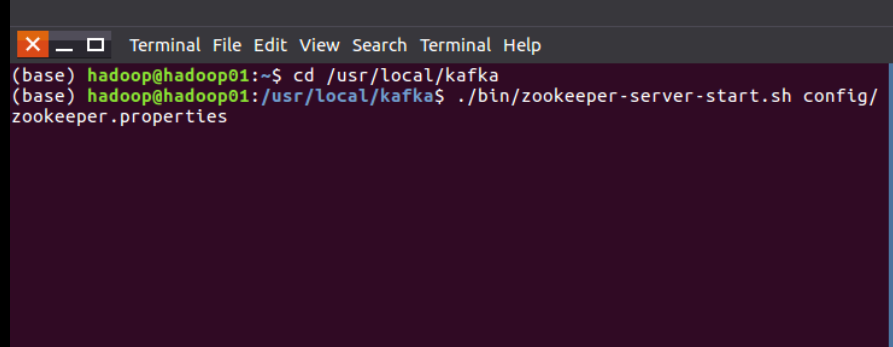
cd /usr/local/kafka
./bin/zookeeper-server-start.sh config/zookeeper.properties
启动完毕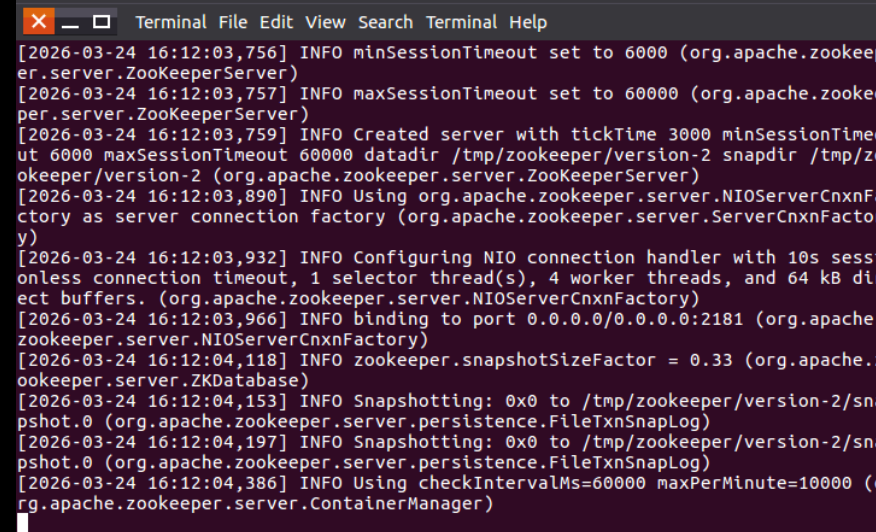
2。启动 Kafka
新终端:
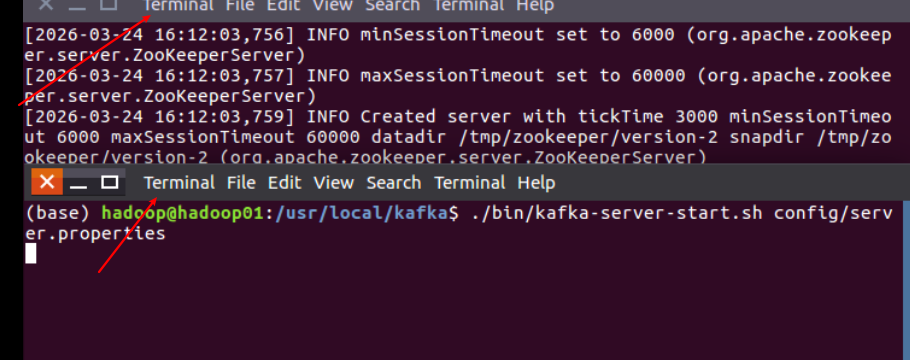
代码
./bin/kafka-server-start.sh config/server.properties
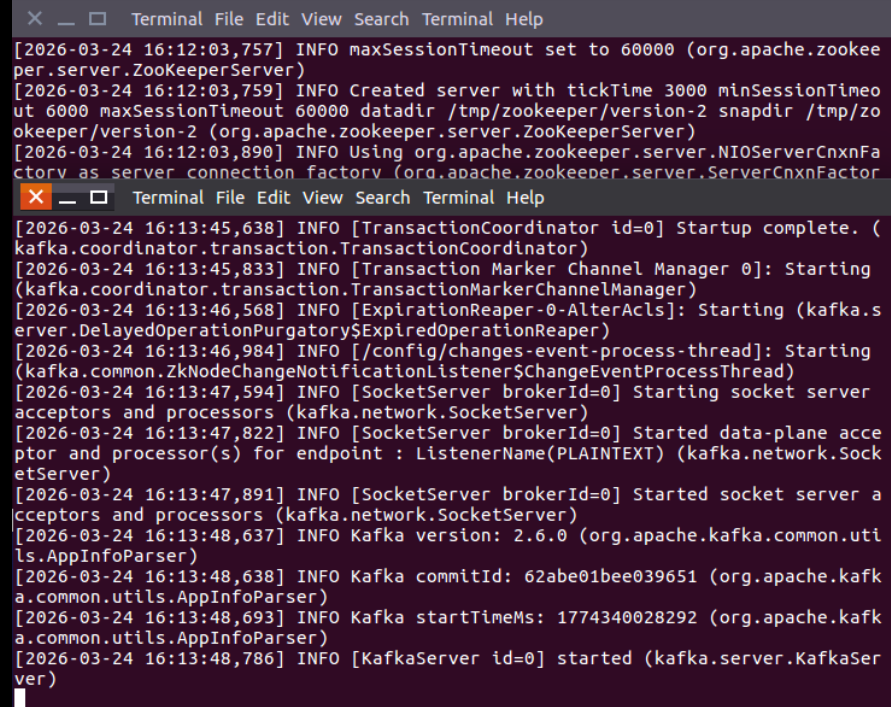
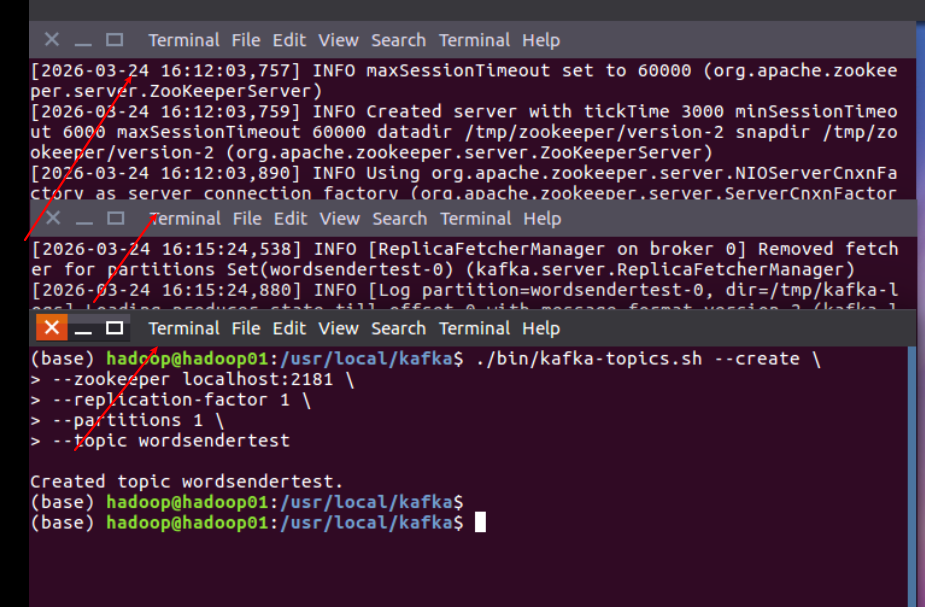
3 。 创建Topic
新终端
./bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic wordsendertest
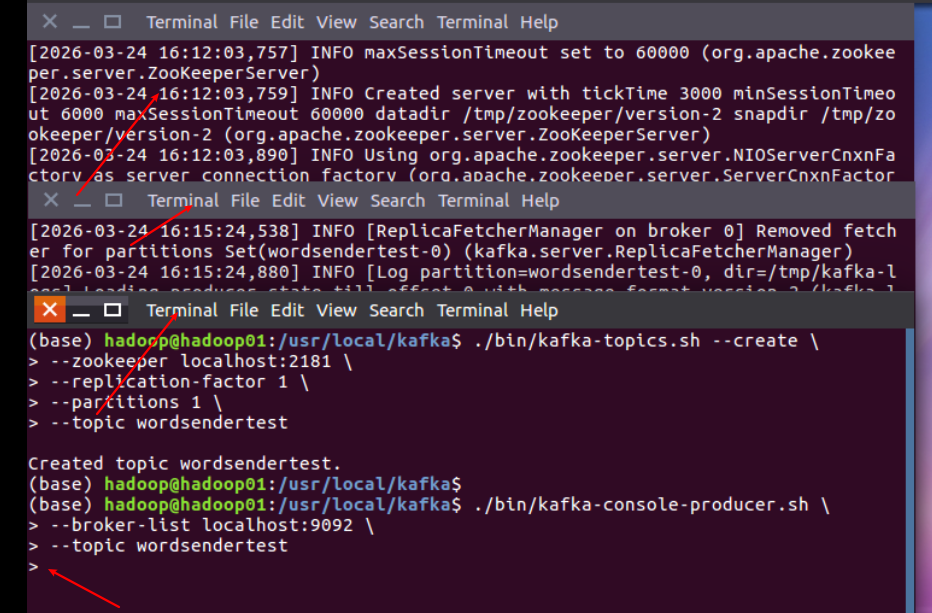
4。打开生产者
./bin/kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic wordsendertest
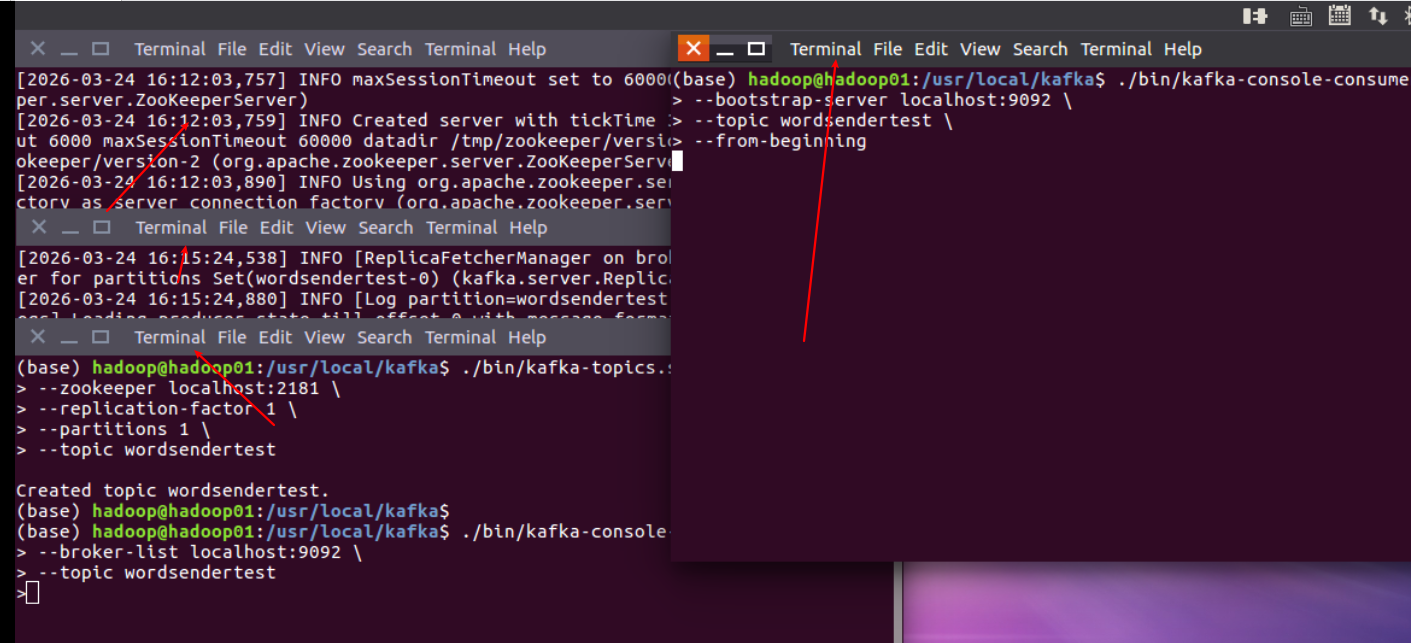
5。 打开消费者
新终端
./bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic wordsendertest \
--from-beginning
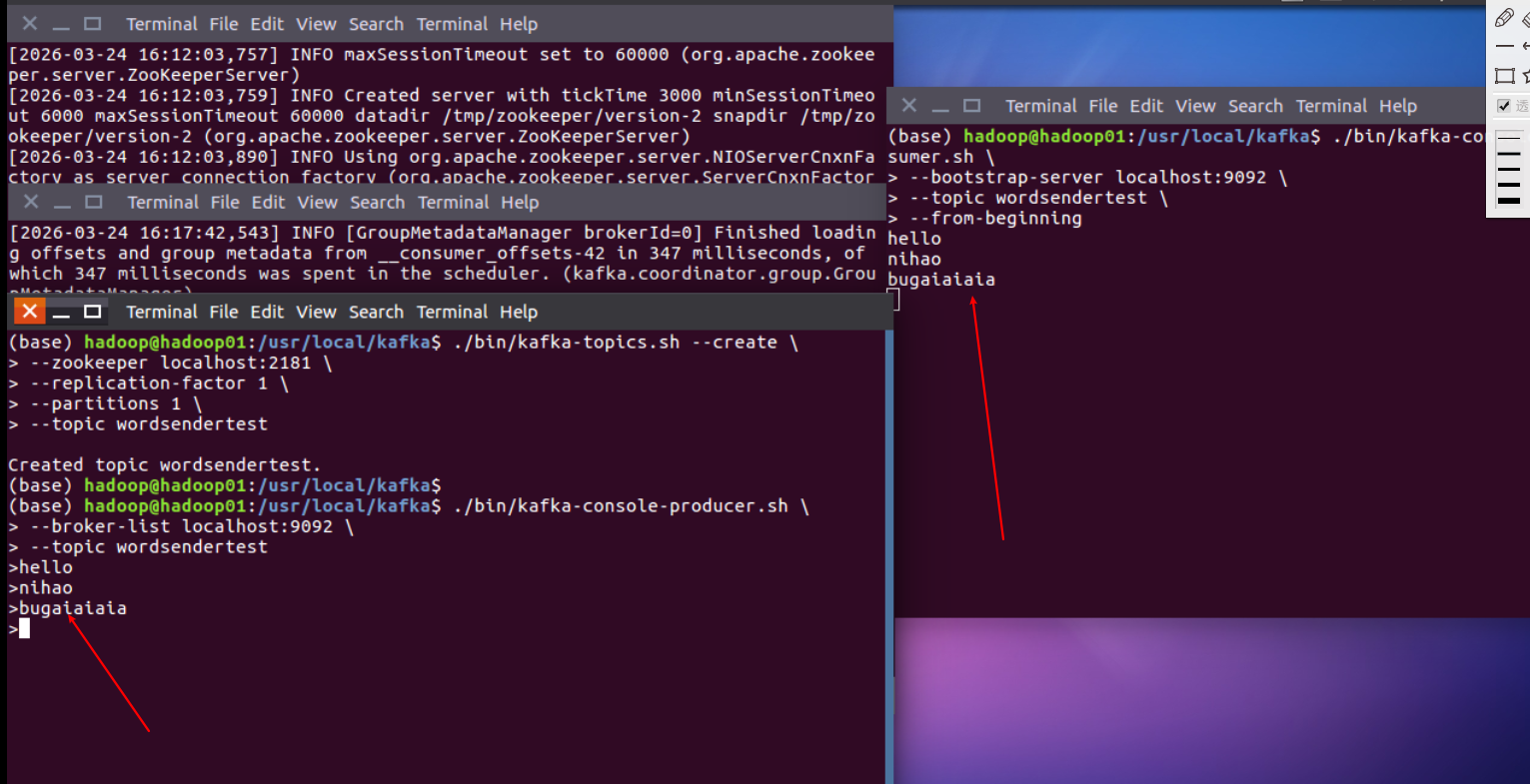
6。 通讯
生产者产生数据
消费者接受数据
Anaconda + Python环境
1。 激活环境:
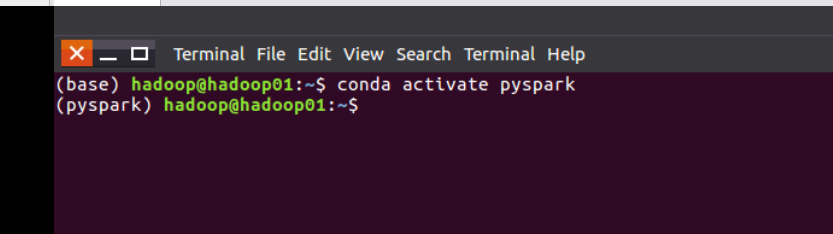
2。 测试
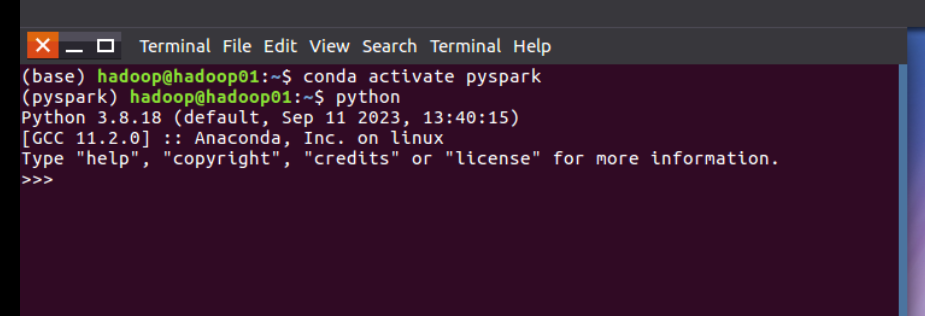
Spark环境搭建流程 PI.py 检测
1。 启动hadoop
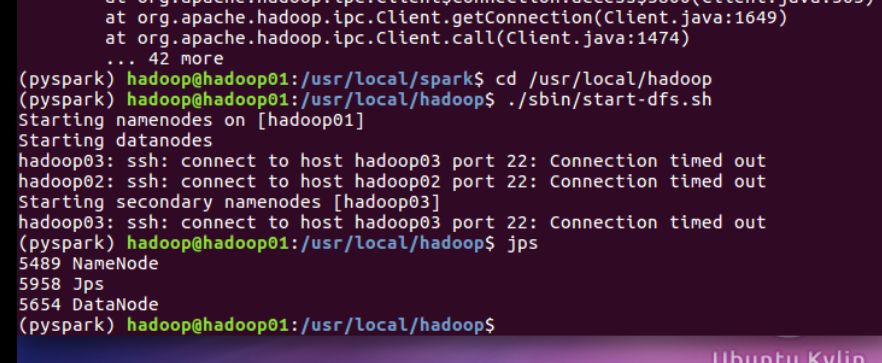
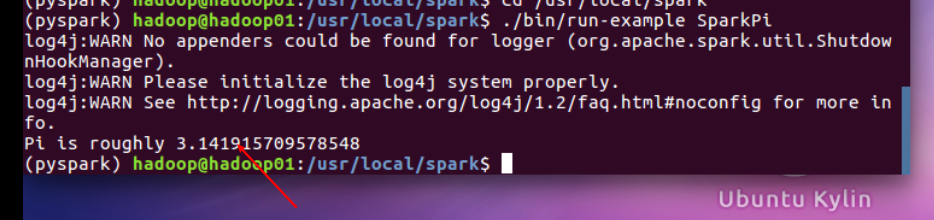
2。 验证 Spark 是否安装成功
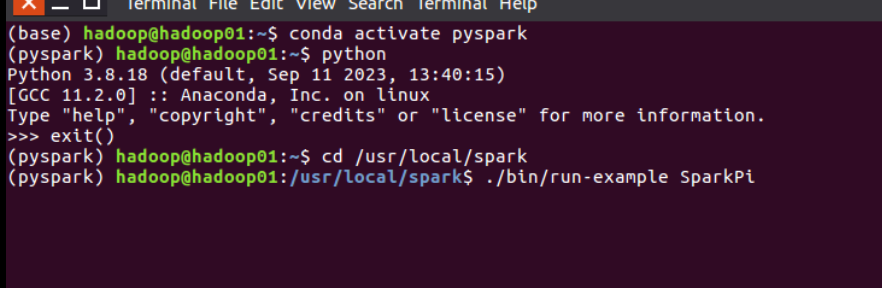
cd /usr/local/spark
./bin/run-example SparkPi
Spark 编程以及pycharm使用
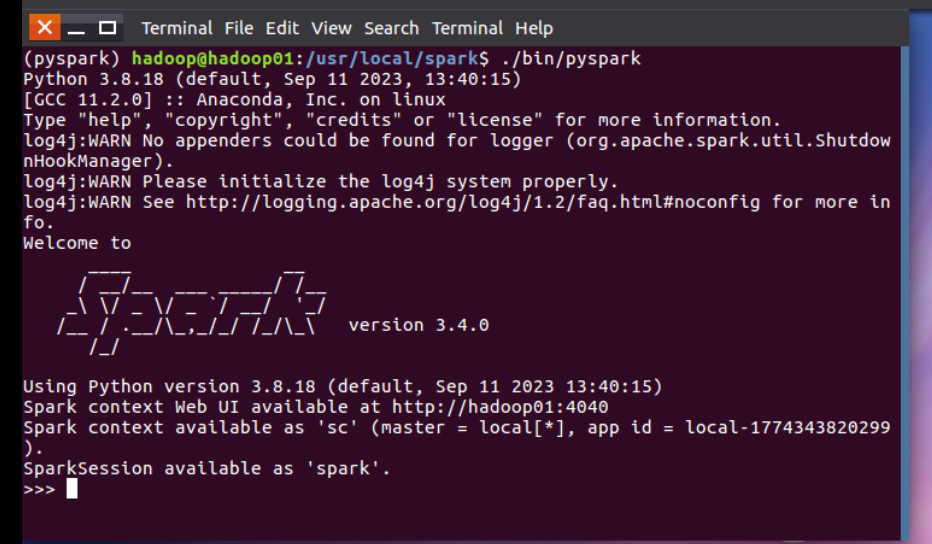
1。 Spark 自带环境确认
cd /usr/local/spark
./bin/pyspark
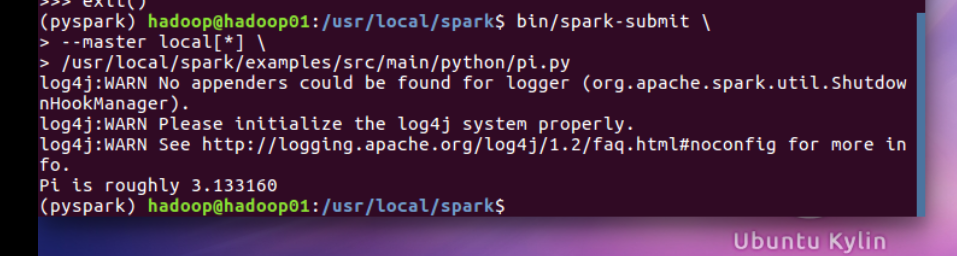
2。 用 spark-submit 提交程序
cd /usr/local/spark
bin/spark-submit \
--master local[*] \
/usr/local/spark/examples/src/main/python/pi.py 10 2>&1 | grep "Pi is roughly"
3。 写一个最简单的 Spark 程序
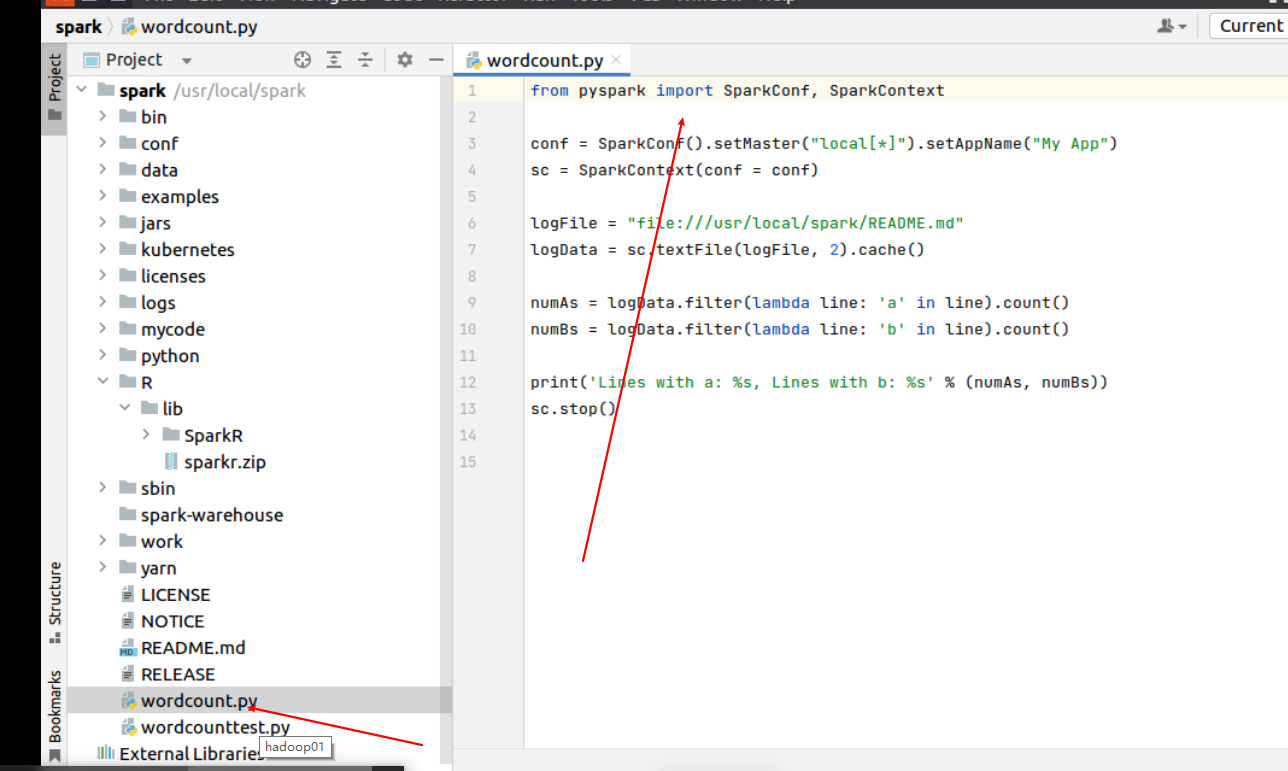
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("My App")
sc = SparkContext(conf = conf)
logFile = "file:///usr/local/spark/README.md"
logData = sc.textFile(logFile, 2).cache()
numAs = logData.filter(lambda line: 'a' in line).count()
numBs = logData.filter(lambda line: 'b' in line).count()
print('Lines with a: %s, Lines with b: %s' % (numAs, numBs))
sc.stop()

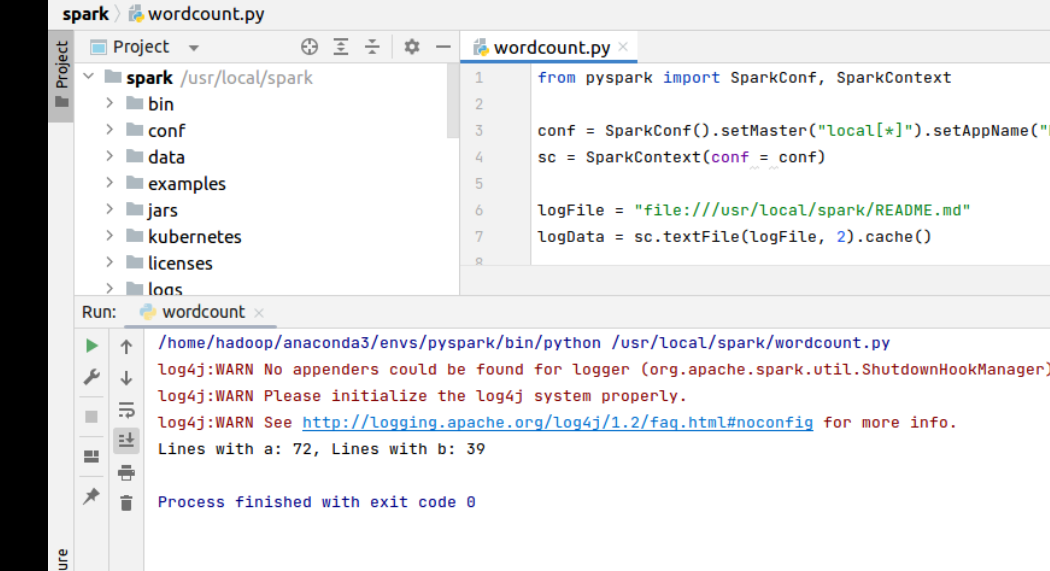
python WordCount.py
截图缺失
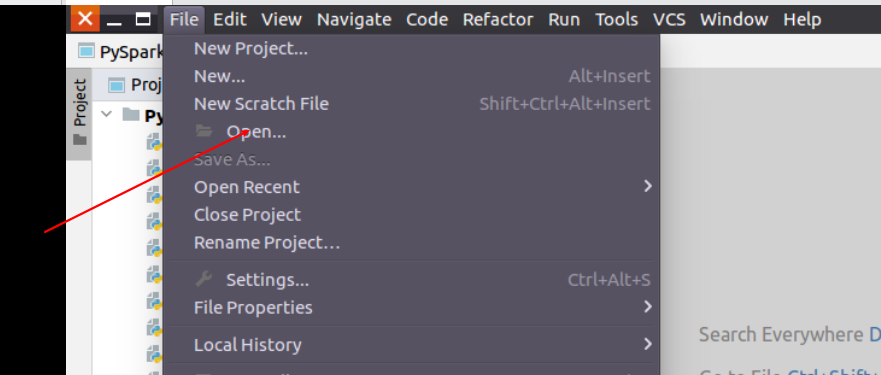
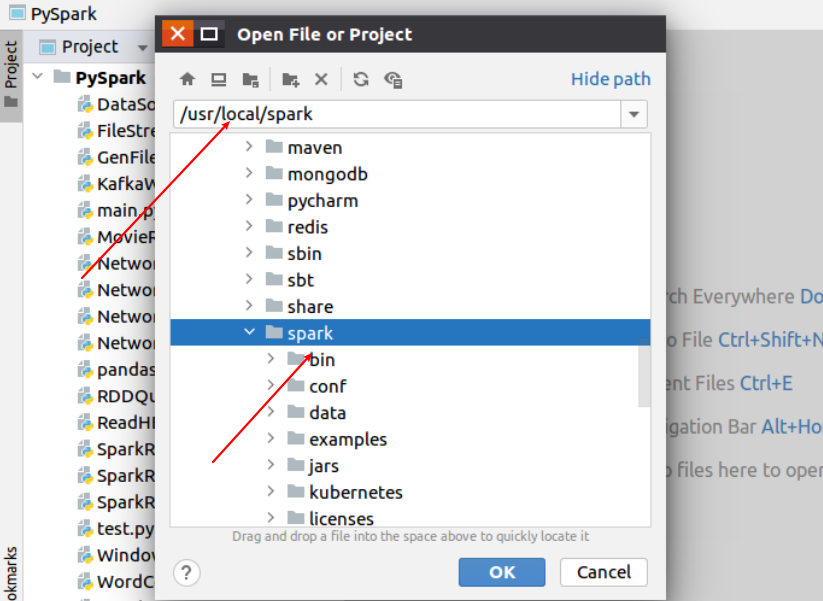
4。 pycharm
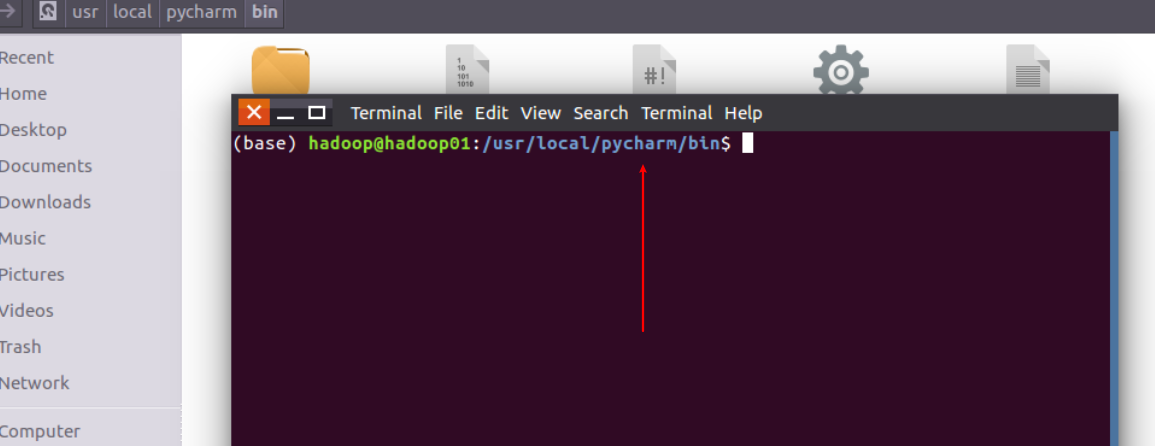
/usr/local/pycharm/bin
./pycharm.sh

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)